

一篇文章彻底搞懂哈希哈希游戏平台表
哈希游戏作为一种新兴的区块链应用,它巧妙地结合了加密技术与娱乐,为玩家提供了全新的体验。万达哈希平台凭借其独特的彩票玩法和创新的哈希算法,公平公正-方便快捷!万达哈希,哈希游戏平台,哈希娱乐,哈希游戏HashTable就是散列表((哈希表),将从下面几个方面来讲解散列表的原理
什么叫散列技术呢?一句话来说,散列技术是一种查找技术,而且是一种一步到位的查找技术
在说散列技术之前,我们先回忆一下 顺序表查找 二分查找,插值查找这些查找技术是怎么操作的.
在这些查找技术中,我们先确定要查找的值key,然后在待查找的元素集合中与其中元素进行对比,然后找到要查找元素位置index
在散列查找技术中,不用逐个的对比,确定要查找的值key后,再通过一个函数f把key传进去计算,计算结果即要查找元素的位置index
顺序/二分/差值查找:要查找元素key-与待查找集合中的元素对比-找到要查找元素的位置index
散列查找:要查找元素key-直接通过函数f计算出要查找元素的位置index
这也就说明了用散列技术查找的时候,我们一开始存储元素就应该事先按照函数f所对应的规律去存储元素, ,使得我们存进去的元素key的位置是f(key),这样我们用函数f查找的时候才能奏效.所以说散列技术既是一种查找技术,也是一种存储技术.
这里的函数法f就叫散列函数(哈希函数),采用散列技术所建立的元素存储空间就是散列表(哈希表),元素的存储位置就叫散列地址(哈希地址)
1.散列技术不适合集合中重复元素很多的情形,因为这样的话同样的key,就会对应很多index,比如下面这种情况

2.散列技术不适合范围查找 也不适合查找最大值,最小值.这些都无法从散列函数中计算出来.

首先应该计算简单,因为如果计算太复杂就会导致每次查找时计算散列地址耗费太多时间
其次应该保证计算出来的哈希地址空间分布均匀,这样可以节省空间,同时也减少了为处理冲突而耗费的时间.
在讨论散列技术的优缺点的时候 我们说其有一个缺点就是会产生冲突,即不同的key却会有相同的散列地址index

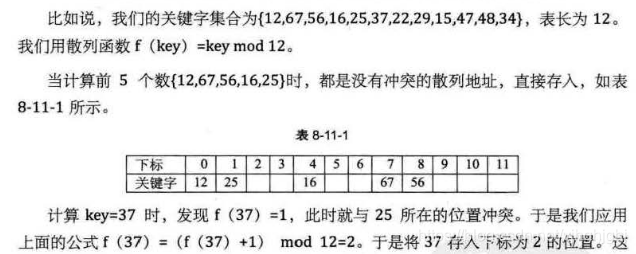
上面我们说,散列技术的复杂度可以达到常数时间,但是用线性探测的话我们需要不断的解决冲突问题,
所以在这种情况下,平均情况是线性巡防半个表格,最坏情况是线性巡防整个表格.远不及我们的期望时间.
主要原因就在于每次插入元素时总是难以避免冲突,一旦碰到冲突就得不断解决碰撞问题,最后才找到一个空,
在这个空里面安置了以后,又使主集团增大,又增加了下一次插入数据碰撞的概率.


叫这个名字可能是因为表格内每个单元涵盖的可能不止一个结点,可能是一桶结点.
最后我们还要注意一点,虽然链地址法不要求表格大小必须为质数,但是SGI STL中仍然以质数来设计表格大小
并且将28个质数计算好,以备随时访问,用来查询在这28个质数中最接近并大于某数的质数

HashTable里面定义了一个专属的节点配置器,用来更好的以结点为单位开辟空间
这个构造函数有三个参数,第一个表示要构造哈希表结点多少,第二个是散列函数,即计算元素位置的函数型别
可以看到在initialize_buckets中,先计算了接近n的质数buckets空间大小,然后在里面都填充了类型为node*的空指针
判断依据是如果插入后元素个数大于buckets vector大小,则重建表格,否则返回
如果不需要重建,或者重建完成了以后,在去执行插入新节点操作(需要保证插入结点不重复)

求解元素地址就是求出元素位于哪一个bucket内,这本来是hash_function的任务,SGI把这个任务封装了一层,先交给bkt_num
为什么要这么做呢?因为有些元素比如字符串,无法直接拿来对hash_table的大小进行取模运算.这个时候就要通过bkt_num函数先进行一些转换.
hash table表格内的元素称为桶(bucket),而由桶所链接的元素称为节点(node),其中存入桶元素的容器为stl本身很重要的一种序列式容器——vector容器。之所以选择vector为存放桶元素的基础容器,主要是因为vector容器本身具有动态扩容能力,无需人工干预。
向前操作:首先尝试从目前所指的节点出发,前进一个位置(节点),由于节点被安置于list内,所以利用节点的next指针即可轻易完成前进操作,如果目前正巧是list的尾端,就跳至下一个bucket身上,那正是指向下一个list的头部节点。
当向容器添加元素的时候,会判断当前容器的元素个数,如果大于等于阈值即当前数组的长度乘以加载因子的值的时候,就要自动扩容啦。
扩容(resize)就是重新计算容量,向HashMap对象里不停的添加元素,而HashMap对象内部的数组无法装载更多的元素时,对象就需要扩大数组的长度,以便能装入更多的元素。
最初的 C++ 标准库中没有类似 hash_map 的实现,但不同实现者自己提供了非标准的 hash_map。 因为这些实现不是遵循标准编写的,所以它们在功能和性能保证方面都有细微差别。从 C++ 11 开始,hash_map 实现已被添加到标准库中。但为了防止与已开发的代码存在冲突,决定使用替代名称 unordered_map。这个名字其实更具描述性,因为它暗示了该类元素的无序性。
最初的 C++ 标准库中没有类似 hash_set的实现,但不同实现者自己提供了非标准的 hash_set。 因为这些实现不是遵循标准编写的,所以它们在功能和性能保证方面都有细微差别。从 C++ 11 开始,hash_map 实现已被添加到标准库中。但为了防止与已开发的代码存在冲突,决定使用替代名称 unordered_set。这个名字其实更具描述性,因为它暗示了该类元素的无序性。